
In December we held a hackathon to celebrate the 200th birthday of Ada Lovelace. In the last post, the results of the baking competition were mentioned along with our efforts to program the Analytical Engine emulator. Although I briefly alluded to a project I undertook last month which built upon these ideas, the implementation was only completed a few hours before I had to present it in a talk. As such, the actual results are hitherto undocumented, except in the deepest recesses of a GitLab repository.
The project was to implement a machine-learning algorithm within the confines of the Analytical Engine (which amounts to about 20 kilobytes of memory and a very minimalistic instruction set). If you have 35 minutes to spare, here is my talk introducing the project. My apologies for the hesitant beginning; the talk was unscripted:
It transpired that, at the time of the talk, there were a couple of mistakes in the implementation; I was later able to detect and remove these bugs by writing additional Analytical Engine code to facilitate debugging. After making these modifications, the machine-learning code learned how to recognise handwritten digits surprisingly well.
As mentioned in the talk, a simple neural network would occupy too much memory, so I implemented a deep convolutional network instead (with extra optimisations such as using the cross-entropy cost function and L2 regularisation in the final fully-connected layer). Specifically, there are 5 feature-maps in the first convolutional layer, and 10 in the second convolutional layer:
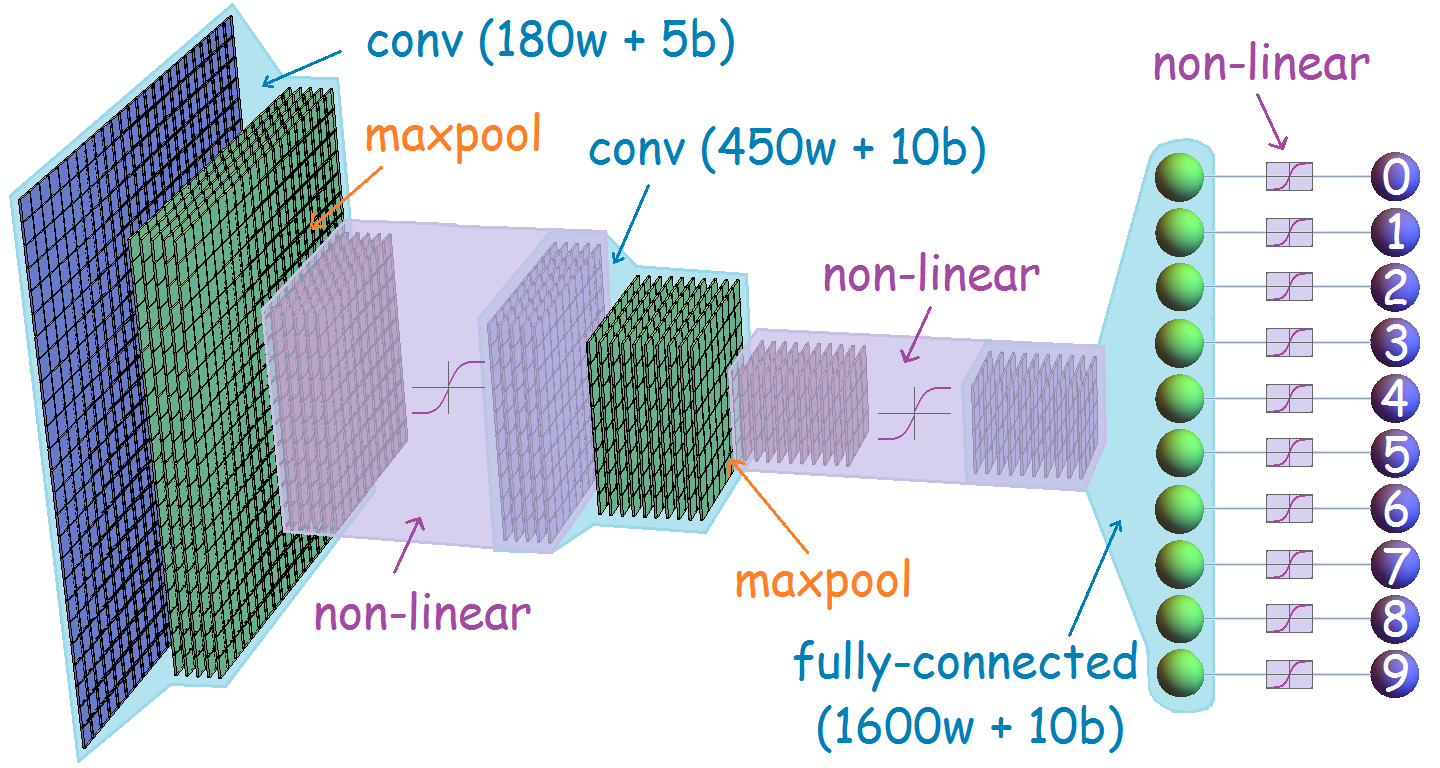
Code generation was performed by a combination of a Bash script (for overall orchestration) and several Python scripts (for tasks such as generating code for each layer, implementing a call-stack to enable subroutines, and including the image data in the program). The generated code comprises 412663 lines, each one corresponding to a punched card for the actual Analytical Engine. Even if the punched cards were each just 2mm thick, the program would be as tall as the Burj Khalifa in Dubai!
The following progress report shows a dot for an incorrect guess and an asterisk for a correct guess; it is evident that the code is rapidly learning:
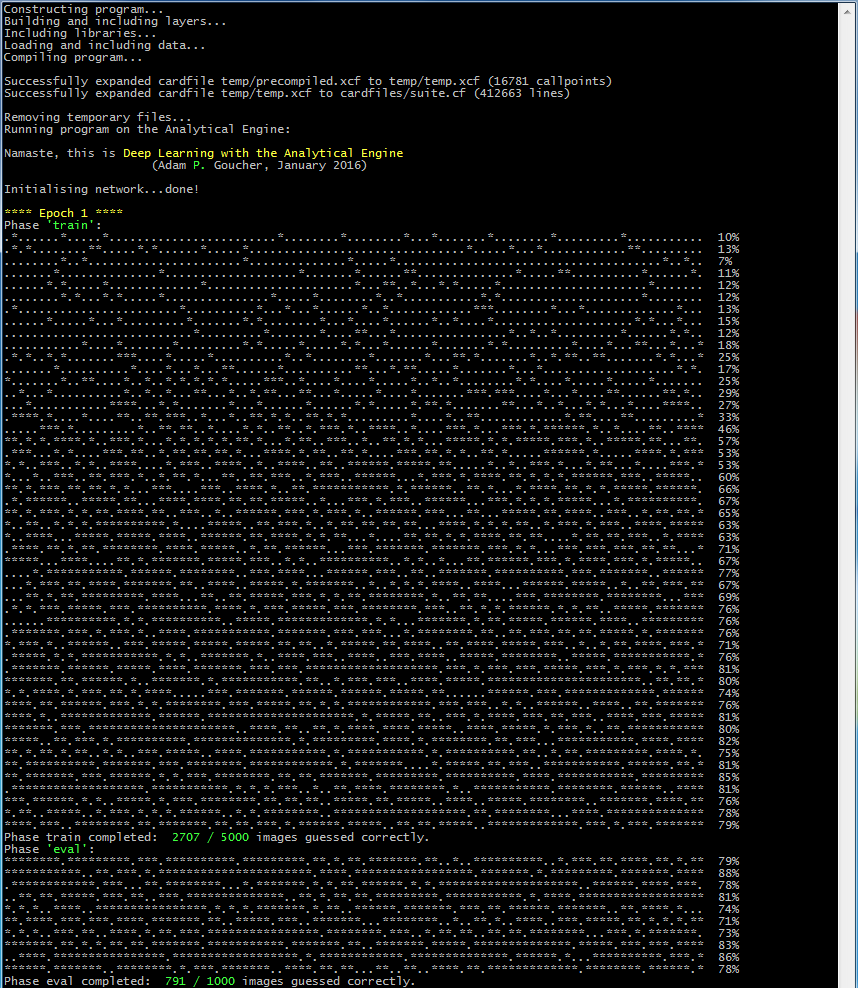
You can see during the first training epoch that its performance increases from 10% (which is expected since an untrained network equates to random guessing, and there are 10 distinct digits {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}) to 79% from training on 5000 images. This was followed by a testing phase, in which a different set of 1000 images were presented to the network without the labels; unlike in the training phase, the network isn’t given the labels for the testing images so it cannot learn from the test and subsequently ‘cheat’. The testing performance was 79.1%, broadly in line with its performance on the training data towards the end of the epoch as one would expect.
We then repeat this process of training on 5000 images and evaluation on 1000 images. The performance improved again, from 79.1% to 84.9%. After the third epoch, it had increased to 86.8%, and by the end of the ninth epoch it had exceeded 93%. At that point I accidentally switched off my remote server, so the results end there. If you set the program running on your computer, it should overtake this point after about 24 hours.
[Edit: I subsequently tried it with 20000 training images and 10000 evaluation images, and the performance is considerably better:
- 89.69%
- 93.52%
- 94.95%
- 95.53%
- 95.86%
- 96.31%
and is continuing to improve.]
Theoretically the architecture should eventually reach 98.5% accuracy if trained on 50000 images (confirmed by implementing the same algorithm in C++, which runs about 1000 times more quickly); I urge you to try it yourself. Complete source code is available on the Deep Learning with the Analytical Engine repository together with additional information and links to various resources.
Pingback: 2 – Deep Learning with the Analytical Engine
Pingback: March miscellany | Complex Projective 4-Space
“Even if the punched cards were each just 2mm thick …”
Aren’t punch cards acutally thinner than a millimeter? Did you mean 0.2 mm?
Jacquard looms typically used thicker cards, before punched card thickness was standardised: http://whatis.techtarget.com/reference/History-of-the-punch-card
Pingback: vog comments on "Deep Learning with the Analytical Engine"
Pingback: d42: Deep Learning with the Analytical Engine – AI
Pingback: Knowledge is Power | Charles Babbage’s Analytical Engine Takes on Deep Learning
Pingback: Charles Babbage's Analytical Engine Takes on Deep Learning – suzguru.com
Pingback: 查尔斯·巴贝奇的分析引擎在深度学习领域一展身手 | 一迈 IM-AI