
A couple of years ago I described a prime p which possesses various properties that renders it useful for computing number-theoretic transforms over the field 
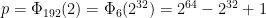
where the first of these equalities uses the identity that:
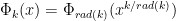
where rad(k) is the product of the distinct prime factors of k.
It transpires that at approximately the same time, this field and its properties were rediscovered by the authors of the cryptographic protocol Plonky2. Remco Bloemen has written an article on this prime, which he calls the Goldilocks prime. Remco’s article is very much worth reading; it contains a bunch of new things not present in my original article, such as a fast implementation of modular inversion* based on the binary GCD algorithm, as well as a comprehensive discussion of Schönhage’s trick and some closely related variants.
*which can be improved by a further 20% as implemented here.
Besides convenient real-world properties such as fitting neatly into a machine-sized integer, there are two important mathematical properties of p:
- p − 1 is divisible by
, so
- 2 is a primitive 192th root of unity, so multiplying an element of the field by a 192th root of unity (or indeed a 384th root of unity, by Schönhage’s trick) is particularly efficient. Since 192 has a large power-of-2 divisor (64), this means that we can use radix 64 for implementing these NTTs efficiently.
This prime has a much larger cousin with very similar properties:
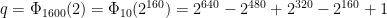
We’ll call this the Osmiumlocks prime, because it’s in some sense a heavier version of the Goldilocks prime.
In this case, 2 is a primitive 1600th root of unity, and 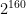
The beneficial properties of the Osmiumlocks prime q as compared with the Goldilocks prime p are that it’s sufficiently large to use for cryptography (for example, as the base field for an Edwards curve) and that it allows vastly longer power-of-two-length NTTs. You would only be limited by the maximum length of a power-of-two-length NTT over this field if you could store 2^160 words in memory; unless each word could be stored in fewer than 100 atoms, there are insufficiently many atoms inside the planet to build such a machine!
The disadvantage is that, being 640 bits long, field elements no longer fit into a 64-bit machine word. We’ll address this issue shortly.
Also, whereas multiplying by cube roots of unity was efficient in the Goldilocks field, it’s no longer efficient in the Osmiumlocks field; conversely, multiplying by fifth (and, less usefully, twenty-fifth) roots of unity is now efficient whereas it wasn’t in the Goldilocks field. All of the roots of unity in the Goldilocks field still exist in the Osmiumlocks field, though, because q − 1 is divisible by p − 1.
An unlikely alliance
I originally saw these two primes p and q as competitors: two primes with similar properties but very different sizes. It transpires, however, that the properties of p help to address the drawbacks of q, namely its inability to fit into a single machine word.
How would we implement arithmetic modulo q? If we represented it as 640/64 = 10 machine words, then we’d need 100 multiplication instructions (together with carries and suchlike) to implement multiplication using the ordinary method for integer multiplication. Instead, we’ll make use of the following observation:

This means that the field 


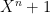
If we set n = 32, so that 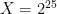
We can do this negacyclic convolution efficiently using NTTs if we have efficient 64th roots of unity, which indeed we have in the original Goldilocks field! We can therefore compute one of these length-32 negacyclic convolutions over the Goldilocks field
We’ll need other operations, such as shifts and adds, but these tend to be cheap operations. Whether or not this is worthwhile depends on the size of the hardware multiplier. Many GPUs implement a full 64-bit product as many individual calls to a smaller (16- or 32-bit) hardware multiplier, so there we would experience a greater advantage from this NTT-based approach.
Also, the relevant operations vectorise very well: on a GPU, each warp consists of 32 threads, and we can have the ith thread in a warp hold the coefficient of 
Is it possible to do a fast inversion by doing a negacyclic NTT, inverting pointwise, and undoing the NTT? I feel like there might be a problem with if the image of the NTT is zero somewhere.
The NTT should only have a zero if the input is noninvertible mod 2^800+1, which can only happen if it’s divisible by either 2^160+1 or the Osmiumlocks prime. In the first case, you can add the NTT of the Osmiumlocks prime to break the divisibility, and in the second case, it’s zero modulo the Osmiumlocks prime.