
Tim Hutton has announced the release of Ready 0.5, which is now able to support cellular automata and reaction-diffusion systems on three-dimensional honeycombs. There are a few sample patterns on Penrose tilings as well.
Replicators and Feynman diagrams
On the subject of cellular automata, Nathan Thompson discovered a variant of Conway’s Game of Life in 1994. It was termed ‘HighLife’ due to the existence of a small replicator, which copies itself every twelve generations. An early discovery was that the replicator can drag a blinker (cluster of three cells) behind it, translating itself by (8,8) every 48 generations:

The c/6 spaceship in HighLife
For a while, people were unsure what this spaceship should be called. David Bell had recently conceived his second child, Carina (named after the constellation), and there were proposals to name the spaceship after her. Eventually, however, the community settled upon the term ‘bomber’ to describe how it appears to periodically emit small explosions every 24 generations.
Rather than considering these things as two-dimensional clusters of cells changing over time, it is convenient to abstract away most of the details. The replicator and bomber then become very simple objects, which can be viewed as ‘Feynman diagrams’:
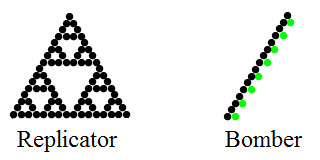
Space and time are represented on the horizontal and vertical axes, respectively; as time progresses, one moves down the diagram. The Feynman diagram for the replicator is Pascal’s triangle modulo 2 (resembling the Sierpinski triangle), whilst the blinker pulled behind the bomber causes it to remain bounded instead of expanding forever. The replicator units killed by the blinker are represented by green dots in the diagram.
The bomber is said to travel at a speed of c/6, which means that (on average) it translates by one cell every 6 generations (timesteps). More precisely, its velocity is (8,8)c/48, as it travels 8 units up and 8 units to the left every 48 generations. This is clearly the fastest possible speed a replicator unit can move at, and is the speed at which an untamed replicator expands.
XOR-extendable spaceships
In 1999, Dean Hickerson wondered whether slower speeds are possible. In theory, a string of replicator units could push a blinker at one end and pull another at the other end. We already have a ‘pull’ reaction (the basic one performed by the bomber); a (5,3) push reaction was found by Dean Hickerson. This is described in the last paragraph of this article.
This would ordinarily be incompatible with the (8,8) pull reaction, since (5,3) isn’t the same vector as (8,8). Fortunately, a parallel replicator can subsequently push it by (3,5), for an overall displacement of (8,8). The Feynman diagram for the push reaction is much more complicated than the pull reaction:
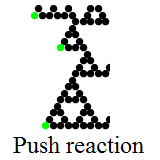
Not much became of this idea. It was realised that such a beast would be colossal (estimated size: 2^60 replicator units), and the idea was abandoned. Occasionally, people talked about the possibility of one of these XOR-extendable spaceships, but no exhaustive searches were done.
Until now, that is. I’ve discovered the first XOR-extendable spaceship in HighLife, which I have named the Basilisk due to its length. Indeed, if printed on graph paper at the scale of one cell per millimetre, it would be long enough to reach the Moon!
Using some linear algebra, I realised that the most fruitful speed to search for was c/69. It’s not too slow, nor too fast, and most importantly the feedback polynomial (a term I’ll elaborate upon later in this article) has a sufficiently large order for me to be confident that c/69 XOR-extendable spaceships can exist. I decided that a good starting point would be to draw the Feynman diagram for the ‘head’ of this spaceship:

The colour of each dot (white or black) is obtained by adding together the two dots above it, modulo 2. This operation of addition modulo 2 is also known as exclusive disjunction, symmetric difference or simply ‘XOR’. Note that the bottom row is identical to the top row, but shifted two dots (corresponding to (8,8) in the original cellular automaton) to the left. These constraints are sufficient to extend the pattern above ad infinitum.
We can do the same for the tail of the spaceship, shown below. The two green dots at the back end correspond to the standard pull reaction exhibited by the bomber spaceship. There are many possible tails, and I had to include all of them in my search program to ensure that a solution was found.

Ideally, we want these two diagrams to ‘match up’ somewhere, so that we can connect the head and tail. This is not easy, since it requires the top row to agree in 46 consecutive bits. It’s quite possible that the string of bits enters a periodic behaviour before a match is found; that’s why we need to search for matches with many potential tails.
It transpires that the string of bits can be generated by a linear feedback shift register. This is defined in a similar manner to the Fibonacci sequence, but where each term depends on the previous 46 terms, rather than the previous 2. Also, it is over the finite field F_2 instead of the integers. The behaviour is obviously cyclic, and a little linear algebra and trial-and-error shows that the period is precisely 987964849939.
Due to the huge number of head/tail pairings, a match occurs well before that. The completed spaceship is just under 85 billion replicator units long. Searching for this required the development of a super-optimised algorithm (several orders of magnitude faster than the naive approach) involving matrix exponentiation and a hash table. After a couple of hours of searching, it stumbled across four potential solutions in quick succession. The one which looked the most promising is shown below:

The Feynman diagram of the Basilisk — click to enlarge
Obviously, I can’t generate an RLE file for the whole pattern. I have, however, produced a proof-of-concept pattern file, featuring an ellipsis to show where I’ve omitted over 84 billion replicator units. You can view and run this in Golly (it works for about 18000 generations before the omission catches up to the ends and destroys the spaceship; the complete Basilisk runs smoothly forever).
Since the proof-of-concept works, and I’ve confirmed by linear algebra that the head and tail do indeed match up, the existence of the Basilisk is rigorously proved.
Great achievement, but I wonder if there’s a chance to find one of more practical size. Perhaps at different speed or maybe by running the search a couple more hours? Because at this point, it’s at about the same stage as caterpillar was when all components were known but nobody assembled it yet.
There are certainly no (significantly) smaller spaceships at the speed of c/69, since the search is breadth-first, exhaustive and finds possible solutions in increasing order. I could try c/63 and c/57, although I think I ruled those out by a much earlier program I wrote in C++. Even if a c/57 spaceship does exist, it’s unlikely to be smaller than 10^8 replicator units (so still unmanageably large).
Dean Hickerson believes that there might be a more efficient ‘push reaction’ capable of operating at a lower period. If it’s significantly faster than the old one, then it should be possible to reduce the period and length (exponential in the period) to something more practical. This would require only trivial alterations to my search program.
Nevertheless, the c/69 spaceship is an explicit example, which wasn’t the case for the Caterpillar before it was assembled.
Have you created a CA rule in Golly that can simulate the Basilisk more efficiently — a three- or four-state rule, let’s say, that runs your “Feynman diagram” of the Basilisk instead of the creature itself? The idea is somewhat along the lines of your two-ON-cell prime number generator — but maybe there are technical reasons why simulation doesn’t work so well here.
I suppose that this would only improve the efficiency by something like a factor of 12 (in time) times 16^2 (in space). But it would certainly allow a much larger fraction of the Basilisk-diagram to be run in Golly, even if we’re still a few orders of magnitude away from taming the entire beast. And since it would be just one or two ridiculously long horizontal lines rather than a ridiculously long diagonal, the compressed RLE might almost be publishable (on DVD anyway!) if not actually runnable…?
By the way, what makes the population of the start phase of the Basilisk so difficult to calculate? It looks as though it *ought* to be straightforward — as the saying goes! — number of replicators in the top line of the ‘Feynman diagram’ times 12, plus the number in the 23rd line times 20, plus nine for the blinkers. Or something like that — I don’t claim to have all the details right! Is it somehow counterintuitively difficult to calculate the exact number of replicators at a given level of the diagram?
Hmm, even the maximum compression of one bit per unit would occupy 10GB of disk space, and would thus be far too large for Golly to handle. I could create a multi-state rule, which actually constructs the Basilisk before running it. Again, Hashlife would choke far before reaching completion.
The only way that we could view this in action would be for me to produce a CDF (computable document format) file containing an applet to allow you to zoom in and out, together with running the pattern forwards and backwards. This is actually feasible, since it wouldn’t need to store the entire Basilisk in memory; using matrix multiplication, it’s possible to jump directly to any point along the length of the Basilisk and compute it.
The difficulty in computing the population is that I don’t know the number of replicators in the top row of the Feynman diagram. It’s 80 billion units long, and stepping through them incrementally to count them would be too time-consuming. The search program jumped by multiples of 2^15 units per step, so that it could achieve a rate of something like 20 million units per second.
Surely an LFSR iteration shouldn’t take more than a few nanoseconds (it’s just AND, population-count, AND, shift, OR (plus an addition to the cumulative population count that the processor can do in parallel with the next iteration of the LFSR))? Even at a microsecond, it would be less than a day to step through 80 billion units.
How are you performing the LFSR iteration? Usually, it involves XORing [a subset of] the 46 previous bits together to obtain the next bit. It might be possible with bitwise operations, but you’ll need at least two 32-bit registers to store each 46-element vector over F_2.
I’m presuming a 64-bit register to store the last 64 bits (and a few other registers for other values), and a processor with a population-count instruction (for Intel processors, that means Nehalem (November 2008) or later); AND it with a bit-mask with the relevant bits of the least (or most) significant 46 set, population-count the result, AND that with constant 1 (giving the parity of the population count, i.e. the result of XORing the relevant bits), and OR that value (the next bit) with the result of shifting the register storing the last 64 bits by 1 bit. The processor should probably be able to pipeline the shift in parallel with the POPCNT and ANDs, and other loop bookkeeping (updating the total population for the top row so far, checking if it’s reached the end of the loop) in parallel with the next iteration of the loop. With a 32-bit processor or one without a population-count instruction, it will indeed be slower.
Thanks, I understand now. I don’t know whether my machine has a population-count instruction; I’ve not needed to use assembly language yet.
My current idea is to do all of the XORs separately (16 of the previous 46 bits are involved in the computation of each bit), but using the bitwise XOR function to do 32 computations in parallel. Specifically, I can start at 32 points in the sequence (separated at regular intervals of 2.5 billion bits) and run them in parallel. Using this technique, I’ll need (2.5*10^9)*15 = 3.8*10^10 bitwise XOR operations in total. This can be halved if I can manipulate 64-bit registers in a single command.
A compiler intrinsic for population count, if available, would generally be preferred to using the assembly instruction directly…. Your approach may be a bit more efficient in terms of XORs, though presumably it needs to keep track of 46 32-bit values (so some state would no longer fit in registers, but would fit in L1 cache), representing the last 46 bits at each of the 32 points in the sequence?
Starting at multiple points in the sequence also allows computing in parallel on a multi-core system (or a distributed computation across many systems, if e.g. you were trying to compute a sum over a sequence a million times longer) – and each core could then in turn do the computations at 32 points together.
Yes, that’s precisely what I had in mind. Ooh, I like the idea of distributing the computation across both cores! I keep forgetting that my laptop is a slightly parallel processor…
Pingback: Assorted stuff | Complex Projective 4-Space