
In nested lattices, we talked about the E8 lattice and its order-696729600 group of origin-preserving symmetries. In minimalistic quantum computation, we saw that this group of 8-by-8 real orthogonal matrices is generated by a set of matrices which are easily describable in terms of quantum gates.
However, something that’s important to note is that quantum states are equivalence classes of vectors, where scalar multiples of vectors are identified. That is to say, the state space of n qubits is the complex projective space 
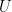
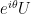
Consequently, the order-696729600 subgroup of O(8) is not exactly the group of transformations in which we’re interested. Rather, we’re interested in its quotient by its centre {±I}. The resulting order-348364800 group G turns out to be very easy to describe without having to mention the E8 lattice!
G is isomorphic to the group of 8-by-8 matrices over the field of two elements which preserve the quadratic form

That is to say, each of the 256 binary vectors of length 8 can be classified as either:
- odd norm, if the number of ‘1’s in the vector is either 1 or 2 (modulo 4);
- even norm, if the number of ‘1’s in the vector is either 0 or 3 (modulo 4).
(Equivalently, the norm is the parity of c(c+1)/2, where c is the popcount (number of ‘1’s) in the binary vector.)
Then G is the group of invertible 8-by-8 binary matrices U which are norm-preserving, i.e. Ux has the same norm as x for all 256 of the choices of vector x.
Why?
To understand this isomorphism, we need to return to the description in terms of the E8 lattice, Λ. We’ll form a quotient of this lattice by a copy of the lattice scaled by a factor of two — the resulting set Λ / 2Λ contains 256 points which form an 8-dimensional vector space over the field of two elements!
Moreover, this set Λ / 2Λ consists of:
- 1 zero point (of even norm);
- 120 = 240 / 2 nonzero points of odd norm (each of which corresponds to a pair of antipodal vectors in the first shell of the E8 lattice);
- 135 = 2160 / 16 nonzero points of even norm (each of which corresponds to an orthoplex of 16 vectors in the second shell of the E8 lattice).
There isn’t an orthonormal basis for this set, so we choose the next best thing: a basis of 8 odd-norm vectors which are pairwise at 60º angles from each other! These, together with the origin, form the 9 vertices of a regular simplex in the E8 lattice. This choice of basis results in the norm having the simple expression we described earlier.
For concreteness, we’ll give an explicit set of vectors:
- e_0 = (½, ½, ½, ½, ½, ½, ½, ½);
- e_1 = (1, 1, 0, 0, 0, 0, 0, 0);
- e_2 = (1, 0, 1, 0, 0, 0, 0, 0);
- e_3 = (1, 0, 0, 1, 0, 0, 0, 0);
- e_4 = (1, 0, 0, 0, 1, 0, 0, 0);
- e_5 = (1, 0, 0, 0, 0, 1, 0, 0);
- e_6 = (1, 0, 0, 0, 0, 0, 1, 0);
- e_7 = (1, 0, 0, 0, 0, 0, 0, 1);
These satisfy 〈e_i, e_j〉 = 1 + δ_ij, where δ_ij is the Kronecker delta.
Computational convenience
In the article on minimalistic quantum computation, we mentioned that the choice of gates with dyadic rational coefficients were particularly convenient, as the matrix entries are exactly representable as IEEE 754 floating-point numbers. For the three-qubit case, this binary matrix representation is vastly more convenient still!
Firstly, an 8-by-8 binary matrix can be stored in a 64-bit processor register. Composing rotations is then reduced to multiplying these binary matrices.
Certain processor architectures support the operation of multiplying two 8-by-8 binary matrices in a single processor instruction! Knuth’s MMIX architecture calls this instruction ‘MXOR’, and there are at least two commercial computer architectures which also support this instruction: the original Cray supercomputer had this for government cryptographic reasons, and (up to one of the operands being transposed in the process) there is a vectorised implementation in the GFNI extension for x86_64. There was also a proposal for an extension for RISC-V with this instruction.
For instruction sets which don’t support MXOR in hardware, you can achieve the same effect with a bunch of bitwise manipulations. Challenge: try to implement MXOR in as few operations as possible using only bitwise Boolean operations and logical shifts. If I counted correctly, I can manage it in 113 total operations (73 Boolean operations and 40 shifts), but I expect it’s possible to do better than this.
What about inverting one of these matrices in G? It turns out that the exponent of G (the lowest common multiple of the orders of the elements) is 2520, so we can invert an element by raising it to the power of 2519. Using a technique which generalises repeated squaring, this can be accomplished by a chain of 15 MXOR instructions.
Interesting to see these 8×8 binary matrices pop up; I explored them a while back in the context of building an associative hash function.
https://math.stackexchange.com/questions/1914853/finding-prime-binary-matrices
Put together a nice fast SSE2 SIMD implementation, but had no idea there were platforms that supported the 8×8 multiply natively!
Ooh, it looks like I misspoke, and there is an x86_64 instruction extension that supports this operation (vectorised):
https://www.felixcloutier.com/x86/gf2p8affineqb
Specifically, if the 8-bit immediate parameter b is set to 0, then this is equivalent to performing a vectorised MXOR(transpose(op1), op2) operating on each 64-bit block of the inputs.
There’s also a RISC-V implementation proposal (section 2.8 of https://github.com/riscv/riscv-bitmanip/blob/master/bitmanip-0.92.pdf ), which is what alerted me to GF2P8AFFINEQB. It confirms that the instruction was present in the Cray (as does http://palms.princeton.edu/system/files/hilewitz_asap_08.pdf which talks about 8×8 and larger bit-matrix multiplication operations).
Strangely, I can’t find any reference to the instruction being present in POWER9, so it’s plausible that I misremembered and was thinking of the RISC-V proposal all along. I’ll update the article accordingly.
Intel has an optimized crypto library you could trawl for fast finite field operations:
https://github.com/intel/ipp-crypto
https://software.intel.com/content/www/us/en/develop/documentation/ipp-crypto-reference/top/finite-field-arithmetic.html