
I have received numerous complaints (from the same person) that some of the content on cp4space is completely ridiculous. Of course, posting more serious mathematics would not solve the issue, since it would not alter the fact that, on cp4space, there are already several ridiculous posts. Hence, the only logical alternative is to make those ridiculous posts appear comparatively serious, by instead writing a single article of unparalleled silliness.
So, it occurred to me to mention a rather intriguing discovery I made. Usually, mathematical discoveries take a long period of dedication, since all of the low-hanging fruit has already been claimed by previous mathematicians. This, however, is something of an exception.
The banana was originally considered a rather exotic fruit (c.f. this video), but over time it has become accepted as being mundane and banal, no qualitatively different from the more indigenous apples and pears that have a habit of hitting unexpectant Trinity mathematicians. It is renowned for having a constant positive curvature and zero torsion. Hence, you can imagine my surprise when I encountered a banana with a point of inflection:

Yes, it’s a banana shaped like an integral sign. This is definitely noteworthy, since it opens up a whole world of new possibilities. After suitably resizing, it was not too difficult to state the divergence theroem using this more colourful substitute for the integral sign:
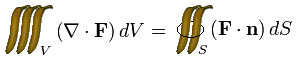
See how the equation suddenly comes to life? How much better it looks than the boring LaTeX-rendered \int symbol? How you’ve been spending years without realising the potential for fruit to feature in practically every piece of applied mathematics you perform?
Well, you have no excuse now. Here are some icons corresponding to the possible variants of the integral sign, together with the equivalent LaTeX commands:
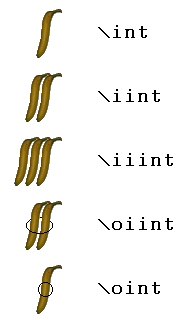
We can use the divergence theorem, for instance, to prove the uniqueness of a solution to Poisson’s equation subject to a Dirichlet boundary condition.

As you can imagine, there is no limit to the amount of enjoyment you can derive from banana integrals. In fact, if you determine the conditions for existence and uniqueness of solutions to the Navier-Stokes equations, then you could even win $1000000 from the Clay Mathematics Institute and have fun at the same time!
Bananaliscious
The first main equality in the proof is backwards!!! (Illogical ordering in chains of equalities is a pet peeve of mine.)
You’re supposed to read the first two lines boustrophedonically, starting from the zero.
Presumably that’s what annoys Gunnar, people writing chains of equalities boustrophedonically.
No need to end the word with -ically, since boustrophedon can already be used as an adverb.
Don’t be ridiculous. This is English, and, as with many other languages, we like giving loanwords native endings in order to give people some clue how to parse them.
“He walked boustrophedon through the hall”: silly name for a dog if you ask me.
“He walked boustrophedonically through the hall”: much better.
Technically, each is equally ridiculous since basically no one uses words derived from boustrophedon.
You shouldn’t be deriving anything on this page. The post is all about integrating.
^I completely coincide with that. No deriving.
I approve of the humorous pun. 🙂
Pingback: Latent Dirichlet Allocation is … | What is this ?
Pingback: The Not-Very-Random-At-All Graph | Complex Projective 4-Space
Pingback: Category of scones | Complex Projective 4-Space
Reblogged this on thankyouforstopping and commented:
INTEGRAL BANANA. I believe, I believe, I believe!