
Robin Houston recently discovered a rather interesting formula for the determinant of an n-by-n matrix. In particular, the formula improves upon the best known upper bound for the tensor rank of the determinant (viewed as a multilinear map which takes n vectors of dimension n — the rows of the matrix — and outputs the determinant).
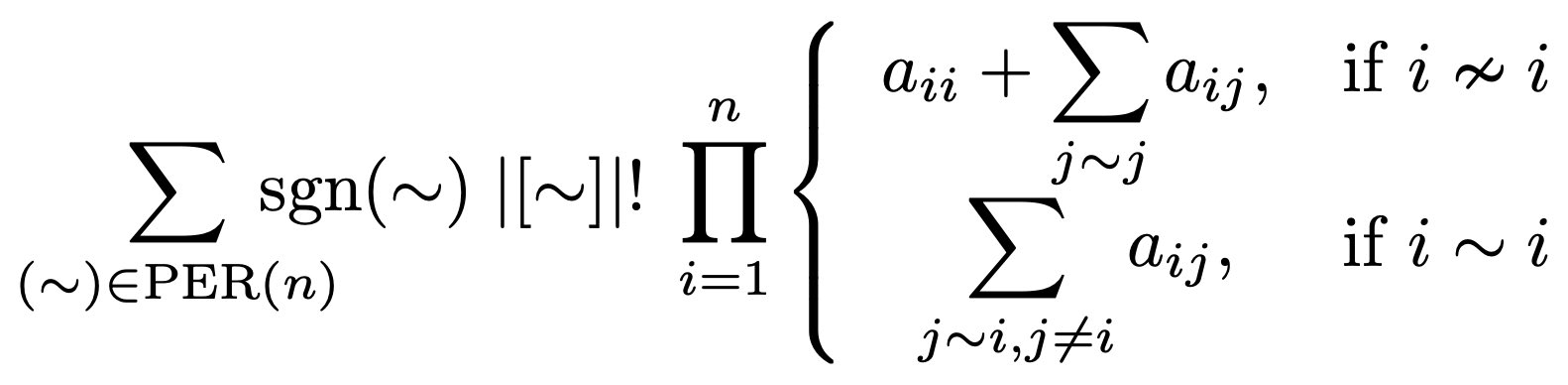
Houston also provided a Mathematica notebook which allows you to verify it for a given finite n (fast for n ≤ 6; very slow for larger n). The linked example shows n = 5, for which there are 52 nonzero terms as opposed to the 120 in the standard Laplace expansion of the determinant.
The sum ranges over all partial equivalence relations (PERs) on the set of n elements. The sign of a partial equivalence relation, sgn(~), is the product, over all equivalence classes S, of (−1)^(|S|+1). The size of a partial equivalence relation, |[∼]|, is simply the number of equivalence classes.
The partial equivalence classes containing singleton classes each contribute 0 to the sum, so these terms can be neglected; the remaining terms are in bijective correspondence with the set of all equivalence classes, in other words the nth Bell number. As each term is a product, over all rows, of linear functions of each row, this establishes that the tensor rank of the determinant is upper-bounded by the nth Bell number.
Houston discovered this identity by thinking geometrically in 3 dimensions and then generalising the result; we shall present a combinatorial proof of the same identity. In particular, we show that the expanded formula simplifies to the usual signed sum over all permutations, and do so without involving any geometrical or linear-algebraic properties of the determinant.
Part I: multiplicity of non-permutations
Observe that if you fully expand Houston’s identity, the resulting monomials are of the form 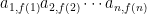
Also, from the definition, these functions have the property that if x is a fixed point of f, then there are no other elements y such that f(y) = x. This is a strictly weaker condition than injectivity, so some of these monomials that appear in the expansion do not belong in that of the determinant; we shall therefore need to show that these monomials appear with a coefficient of 0.
Given such a function f, which terms of Houston’s identity contain the corresponding monomial when expanded out? Let’s visualise f as a directed graph on the vertex-set {1, 2, …, n} where each vertex has exactly one outgoing edge and introduce the following terminology:
- Fixed point: a vertex x with f(x) = x (i.e. a self-loop);
- Leaf: a vertex x such that there are no incoming edges, i.e. no y such that f(y) = x;
- Nonleaf: any vertex that is neither a leaf nor a fixed point.
Given such an f, we can characterise precisely the partial equivalence relations ~ which, when viewed as terms in Houston’s identity, give rise to the monomial corresponding to f. In particular, they are those partial equivalence relations ~ which satisfy the following properties:
- If x is a fixed point, then it does not appear in any equivalence class.
- If x and y are nonleaves belonging to the same connected component of the graph, then x ~ y.
- If x is a leaf, then either x ~ f(x) or x does not appear in any equivalence class.
Note that any connected component (other than a self-loop) must contain at least two nonleaves: if x is any vertex in the component, then it follows from the constraints on f that f(x) and f(f(x)) are two distinct nonleaves. Consequently, we can describe a compatible PER with an ordered pair of:
- An equivalence relation R on the set of nontrivial connected components of the graph corresponding to f;
- A (boolean-valued) indicator function ι on the set of leaves of f which specifies which leaves belong to equivalence classes in the PER.
The first term here determines the size of ~ (it’s the same as the size of R). Fixing such an equivalence relation R, the sign of ~ depends on the parity of the number of leaves l such that ι(l) = 1. In other words, if there are any leaves at all, then we have an equal number of positive and negative terms of each size, so they cancel out perfectly.
Part II: multiplicity of permutations
As such, we’ve established that the only monomials that appear with nonzero coefficients are indeed the ones corresponding to permutations! It remains to show that the coefficients are correct, but it means that the analysis is much simpler because we can henceforth assume that f is a permutation. There are no leaves at all, and the nontrivial connected components are cycles.
Letting C be the set of nontrivial cycles, recall that we have a PER ~ corresponding to each equivalence relation R on C. The corresponding term in Houston’s identity has a coefficient of:
![|[\sim]|! \textrm{ sgn}(\sim) = |[R]|! \textrm{ sgn}(R) \textrm{ sgn}(f)](https://s0.wp.com/latex.php?latex=%7C%5B%5Csim%5D%7C%21+%5Ctextrm%7B+sgn%7D%28%5Csim%29+%3D+%7C%5BR%5D%7C%21+%5Ctextrm%7B+sgn%7D%28R%29+%5Ctextrm%7B+sgn%7D%28f%29&bg=ffffff&fg=000&s=0&c=20201002)
where sgn(f) is the sign of the permutation f. Summing over all such R, we get that the overall coefficient of the monomial corresponding to f is:
![\textrm{ sgn}(f) \sum_R |[R]|! \textrm{ sgn}(R)](https://s0.wp.com/latex.php?latex=%5Ctextrm%7B+sgn%7D%28f%29+%5Csum_R+%7C%5BR%5D%7C%21+%5Ctextrm%7B+sgn%7D%28R%29&bg=ffffff&fg=000&s=0&c=20201002)
We want to show that this simplifies to sgn(f). We can rewrite it using Stirling numbers of the second kind:

This sum is the alternating sum of the number of facets of each dimension in a solid permutohedron, so is equal to its Euler characteristic, which is 1 by contractibility. (There’s probably a more direct way to show this using inclusion-exclusion.) As such, it does indeed simplify to sgn(f), thereby establishing the validity of Houston’s identity.
Asymptotics and further discussion
As discussed, Houston’s identity establishes an upper bound of 

over the Laplace expansion, which is a substantial (superexponential!) improvement. The previous state-of-the-art appears to be:
![(\sqrt[3]{1.2})^n](https://s0.wp.com/latex.php?latex=%28%5Csqrt%5B3%5D%7B1.2%7D%29%5En&bg=ffffff&fg=000&s=0&c=20201002)
which is merely an exponential improvement over the Laplace expansion.
For practical calculation of large determinants over a field, it is far more efficient (polynomial time instead of superexponential time) to perform Gaussian elimination to reduce the matrix into an upper-triangular form and then simply take the product along the diagonal, so these asymptotics are less interesting in practice.
However, there still may be practical value in using this algorithm for small determinants, especially in applications where a branch-free algorithm is desired and multiplications are expensive. For example, it gives an 8-multiplication formula for a 3-by-3 determinant, instead of the 9 from the Laplace expansion, although the same author later discovered a simpler 8-multiplication formula which uses fewer additions/subtractions.
Can a formula be found using fewer than 8 multiplications? Even though the tensor rank for the 3-by-3 determinant is known to be 5, which implies that any ‘multilinear’ formula costs at least 8 multiplications, there may be a nonlinear formula which accomplishes the task in fewer multiplications.
This may seem paradoxical, but there’s an analogous situation in fast matrix multiplication: the best known upper bound for the tensor rank of 4-by-4 matrix multiplication is 49, by applying two levels of Strassen’s algorithm, but there is a little-known method by Winograd for multiplying two 4-by-4 matrices over a commutative ring using only 48 multiplications.
Pingback: Tensor rank paper | Complex Projective 4-Space
The link to the notebook on Wolfram gives me a ‘”Sorry, you do not have permission to access this item.”