
This is the first of a projected two-part series of articles about fast-growing functions.
The first part (‘fast-growing functions’) will introduce the concept of a fast-growing hierarchy of functions, use some notation for representing large numbers, make an IMO shortlist problem infinitely more difficult, and solve it by the well-ordering of the ordinal ε_0.
The second part (‘really fast-growing functions’) will describe Harvey Friedman’s n and TREE functions in detail, before exploring models of computation such as Turing machines and lambda calculus to reach and surpass the Busy Beaver function Σ.
Fast-growing hierarchy
We’ll define a sequence of increasingly fast-growing functions. For a relatively slow start, let’s begin with the function f_1(n) = n+2. Applying f_1 to the natural numbers gives the sequence {3, 4, 5, 6, 7, 8, …}.
Now, we use something called recursion to speed things up somewhat. For each positive integer α, we define f_(α+1)(n) = f_α(f_α(f_α(… f_α(2)…))), where there are n−1 copies of f_α. To avoid the ellipses, we can represent this as the recurrence f_(α+1)(n+1) = f_α(f_(α+1)(n)) with initial condition f_α(1) = 2.
So, f_2(n) = 2n and f_3(n) = 2^n. We’ve very quickly moved from addition via multiplication to exponentiation, so it is clear that later terms will be quite fast indeed. The fourth function gives a tower 2^2^2^2^ … ^2 (evaluated from right to left) of n twos. Using Knuth’s up-arrow notation, this is written as 2↑↑n.
Most weak upper bounds encountered in elementary Ramsey theory (chapter 3 of MODA), such as Ramsey’s theorem and van der Waerden’s theorem, correspond to functions early on in this hierarchy (the naïve bound for van der Waerden is roughly f_4, if I remember correctly).
The largest complete graph which can be three-coloured without a monochromatic triangle, an object in Ramsey theory
We also get functions in Ramsey theory which grow more quickly than any of these functions. In the second part (really fast-growing functions), I’ll describe Friedman’s functions n and TREE, the latter being much faster than anything described in this first part.
Coins in boxes
A recent question on the International Mathematical Olympiad involves a sequence of six boxes, each of which initially contain one coin.
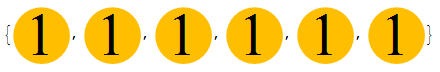
There are two different operations you’re allowed to do:
- Remove a coin from box i and add two coins to box i + 1.
- Remove a coin from box i and swap the contents of boxes i + 1 and i + 2.
The question asks whether it’s possible to get 2012^(2012^2012) (or, in Knuth’s up-arrow notation, 2012↑↑3) coins in the final box. This may seem daunting at first, but it’s not too difficult. Iterating operation 1 allows you to get from (a, 0) to (0, 2a) quite easily. You can get from (a, 0, 0) to (a-1, 2, 0), then (a-1, 0, 4). Applying operation 2, the next step is (a-2, 4, 0), then (a-2, 0, 8), and so on. Recursively, we can get to (0, 2^a, 0).
With more boxes, we can go even further, and get from (a, 0, 0, 0) to (0, 2↑↑a, 0, 0). This pattern generalises in the obvious way.
It transpires that we can indeed get 2012↑↑3 coins in the sixth box. James Cranch asked Maria Holdcroft how many boxes are required to get 2012↑↑(2012↑↑3) coins in the final box, expecting the answer to be seven. She demonstrated that, surprisingly, it’s possible with merely six boxes. Try it yourself!
The Ackermann function
We’ve defined functions f_α for all positive integers α. Can we find a function which eventually overtakes all of them? Indeed, we can; let f_ω(n) = f_n(n). This creates the ‘diagonal’ sequence {3, 4, 8, 65536, 2↑↑↑5, 2↑↑↑↑6, …}. We’ll call this the Ackermann function, although different authors use different definitions. For instance, the Ackermann function could be defined as the maximum number of coins you can get from an initial configuration of n boxes each containing one coin, and it would have a very similar growth rate to every other definition of the Ackermann function.
By the way, ω is the first ordinal greater than all integers. Ordinals are a type of infinity, which I mentioned briefly when discussing combinatorial game theory. I mentioned them again in connection with fusible numbers, and they’re even more important here. You can consider ω to be the limit of the sequence 1, 2, 3, 4, 5, … of natural numbers. The first few ordinals are {1, 2, 3, 4, …, ω, ω+1, ω+2, …, 2ω, 2ω+1, …, 3ω, …, 4ω, …, ω^2, …}, where the ellipses indicate omission of infinitely many terms! We’ll use ordinals as subscripts for this fast-growing hierarchy of functions.
By recursion on f_ω, we can define a new function f_(ω+1). The first few terms are {2, 4, 65536, 2↑↑↑↑…↑↑↑↑65536}, where there are 65534 up-arrows in the fourth term. The largest number used in a serious mathematical proof, Graham’s number, is roughly the 67th term in this sequence produced by f_(ω+1). It is the upper bound for a particular question in Ramsey theory (the corresponding lower bound is 12).
Proceeding in this manner, we can recurse to get f_(ω+2), f_(ω+3), …, and then diagonalise to get f_(2ω). Technically, this should be written f_(ω.2), since ordinal multiplication is not commutative, but notational abuse is common in the world of ordinals. Repeating this process, we get f_(ω.3), f_(ω.4), et cetera, and we can diagonalise to get f_(ω^2). It’s not too hard to see that all ‘polynomials’ (ordinals below ω^ω) can be obtained in this way. Finally, another diagonalisation gives us f_(ω^ω).
Going further, you can get ω^ω^ω, ω^ω^ω^ω and so on. The supremum of these (writing this as ω↑↑↑2 is a gross abuse of notation which will enrage most pure mathematicians) is called ε_0, and is the smallest fixed point of n → ω^n. We’ll get to this later.
Like a C8
Every year, lots of problems are submitted for inclusion in the International Mathematical Olympiad. The reasonably good ones get onto a shortlist, of which six are cherry-picked for the test itself. There are some gems on the shortlist which are neglected, such as this particular question from Austria (classified as C8, i.e. the hardest combinatorics problem on the shortlist in 2009):
For any integer n ≥ 2, we compute the integer h(n) by applying the following procedure to its decimal representation. Let r be the rightmost digit of n.
-
If r = 0, we define h(n) = n/10, i.e. we remove the final trailing zero.
-
Otherwise, if r is non-zero, we split the decimal representation of n into a maximal right part R that consists solely of digits not less than r. The remaining left part is called L (either empty or terminates in a digit less than r). We then define h(n) by concatenating L followed by 2 copies of R−1. For instance, with the number n = 17151345543, we get L = 17151, R = 345543, and h(n) = 17151345542345542.
Prove that, for an arbitrary integer n ≥ 2, repeated application of h eventually reaches 1 in a finite number of steps.
For example, we get 2 → 11 → 1010 → 101 → 1000 → 100 → 10 → 1.
This is non-trivial (hence its rating as C8). Still, we can improve it to make it so much harder! Instead of appending 2 copies of R−1, we append c copies, where c initially begins at 2 and increments every time we apply this process. So, the second time, we append 3 copies of R−1, and so on. This time, starting with n = 2 gives us a longer progression:
2 → 11 → 101010 → 10101 → 10100000 → 1010000 → 101000 → 10100 → 1010 → 101 → 1000000 → 100000 → 10000 → 1000 → 100 → 10 → 1.
Even though C8 was phrased in that way, it’s silly to think of the ‘numbers’ as integers rather than strings of decimal digits. Indeed, the restriction to decimal is arbitrary and unnecessary, and we should instead think of them as sequences of positive integers (the fourth term in the above process is {1,0,1,0,1} rather than the number 10101). Still, we’ll write them without commas for brevity.
Let’s invent a function g which maps strings to ordinals. We’ll map the string “0” to the ordinal g(“0”) = 1. If we have something like “3420001107000”, we’ll map the string to the ordinal ω^g(“231”) + 1 + 1 + 1 + ω^g(“00”) + 1 + ω^g(“6”) + 1 + 1 + 1. Specifically, we separate it into substrings of non-zero digits, decrement the digits in them, map them to ordinals, raise ω to the power of those ordinals, and add them all together. Applying this recursively, our string “3420001107000” is mapped to this ordinal:
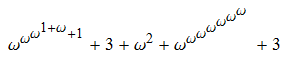
Removing a terminal zero in a string reduces the corresponding ordinal by 1. Applying the other operation causes ω^n to be replaced with (ω^(n−1)).c, where c was defined in the question. This also results in the ordinal decreasing, since c < ω. In other words, are long process has an associated sequence of strictly decreasing ordinals.
Since the ordinals below ε_0 (and indeed all ordinals) are well-ordered, there is no infinite decreasing sequence of them. Hence, this sequence must terminate and reach 1 in a finite amount of time. QED.
It does, however, take a very long amount of time for the process to terminate. If we begin with a single digit n (remember, we’re not restricting ourselves to decimal, so n can be as large as we like), we can define a new function T(n) which gives the number of steps it takes for the process to terminate. For instance, T(1) = 0, T(2) = 16 and T(3) is large. To give an idea as to the size of T(3), the first few strings in the sequence beginning with “3” are:
3 → 22 → 212121 → 212120212120212120212120 → 21212021212021212021212 → 212120212120212120212111111 → 212120212120212120212111110212111110212111110212111110212111110212111110 → …
This function T grows at roughly the same rate as the function f_(ε_0) in our fast-growing hierarchy (by comparison, the original problem C8 only gives a pathetic growth rate around f_4). A very similar function (see Goodstein’s theorem) exceeds Graham’s number for n = 12. It wouldn’t surprise me if the same applies to our function T(n).
Goodstein’s theorem (and probably our modified question C8′) cannot be proved in Peano arithmetic (basic operations together with basic logic and finite induction). This is why C8′ is so much harder than C8, and consequently far too difficult to appear on an IMO. As far as I know, all IMO combinatorics problems can be proved in Peano arithmetic.
Thanks for writing more about this!
Mathematics is sometimes maligned as a sort of “physics of bottlecaps”. Physical operations on bottlecaps correspond to ordinary operations on integers, but when we scale up to really big numbers, there might be different physical laws. For example, some of the bottlecaps might get crushed or fragmented in a sufficiently large pile. I speculate that crossing some barriers (such as the gap between multiplication and exponentiation, or the epsilon zero barrier for Peano arithmetic) could be arranged to act as a warning “Please double check your that your bottlecap laws really do operate out this far.”. Do you think that’s a reasonable speculation?
For example, programmers routinely model the computer’s memory as infinite; but from a mathematician’s standpoint, not only is the computer’s memory finite, but the set of all possible states of the computer, exponentially larger than the computer’s memory (and storage), is also finite. However, nobody would apply finite state machine minimization algorithms to that technically-finite state machine. There’s a connotation that the first word in the concept of “FSM” actually refers to “a small number such as might fit in a single machine register”.
Similarly, the concept of polynomial time in practice connotes small polynomials – coefficients that fit in a single machine register, and exponents logarithmically smaller than that. An algorithm that has exponents in the thousands and coefficients in the googols is likely to be described as “technically polynomial time” or have other hedge-phrases put around it.
Yes, you do have to be careful when assuming that intuitive things generalise. For instance, ‘every injection from a set S to itself is bijective’ is true for finite sets, but fails for all infinite sets. I consider the axioms of ZFC to be ‘definitely true’, and you’re able to prove much more with ZFC than Peano arithmetic (e.g. the well-ordering of epsilon_0 and thus Goodstein’s theorem).
On the other hand, things like the continuum hypothesis are neither intuitively true, nor intuitively false, nor provably true, nor provably false. So, it’s best to keep an open mind and treat both cases separately if necessary. It’s fun when elementary problems turn out to be equivalent (assuming ZFC) to the continuum hypothesis.
I found that the using six boxes and your rules, resulting box might be have more than 2^^(2^^16384) coins, where ^^ means two knuth-up arrows.
I only managed 2^^(2^^4096), so you’ve beaten me. Well done.
Great post, I am very interested to see your follow-up. I have been particularly interested in connecting the Busy Beaver function with the fast-growing hierarchy. My original interest was in finding some concrete way to explain how fast the Busy Beaver machines grows, for example: with 6 states and 2 symbols, are Turing Machines bounded by f_4 functions?
Likewise I’m interested in where the Busy Beaver function could fit into the fast-growing hierarchy of functions. Obviously it grows faster than all fast-growing hierarchy functions defined using computable limit ordinal assignments. Intuitively it seems that if we could extend the fast-growing hierarchy to the Church–Kleene ordinal, it would grow like the Busy Beaver function. But proving things about an ordinal larger than all constructable ordinals is a bit tricky 🙂
Yes, the Busy Beaver function corresponds to the Church-Kleene ordinal in a fast-growing hierarchy. Using iteration and recursion alone, you can’t get anywhere near as far as this (it’s hard to get past epsilon_0).
I’ve written the next post (automatically published some time tomorrow afternoon). I originally intended to mention the Busy Beaver function, but I noticed that TREE(3) can be made into a two-player game. As such, I’m going to cover uncomputable functions in a third post.
It seems like the main problems with going beyond epsilon_0 are not that iteration/recursion are not powerful enough, but that constructively defining ordinal limits past there are difficult. (Perhaps those are two ways of saying the same thing). Below epsilon_0 there is a very clean and orderly Cantor Normal Form for all ordinals and ordinal limits can be defined in a likewise clean and orderly way. I have not heard of such a system for ordinals beyond epsilon_0, do you know of any? The definitions I’ve heard are that epsilon_1 is the second smallest ordinal such that omega^epsilon = epsilon, etc. But this definition does not explain how to construct a sequence of ordinals approaching it, so defining f_{epsilon_1} will be difficult. But perhaps I should wait to see your next post 🙂
With the fixed point idea, you can get all the way up to the Feferman-Schütte ordinal. Beyond there, there’s no canonical form specifying ordinals. I’ve seen the small Veblen ordinal (corresponds to the TREE function) defined in terms of *uncountable* ordinals, which is extremely non-constructive.
You must be haven’t heard about Chris Bird, he defined recursively all ordinals up to Bachmann-Howard. Actually, epsilon_1 is a mere epsilon_0 tetrated to omega, or epsilon_0^(epsilon_0^(epsilon_0(…(epsilon_0^epsilon_0)…) (omega epsilon_0’s).
epsilon_2 = epsilon_1 tetrated to omega
epsilon_3 = epsilon_2 tetrated to omega, and so on.
Moreover, Chris Bird packs ordinals into notation, e.g. f(n) = {n,n [1 \ 2] 2} grows as fast as f_{epsilon_0}(n)
Pingback: TREE(3) and impartial games | Complex Projective 4-Space
T(2) is not 16. If you replace R with 3 copies of R-1, then 2 transforms into 111, not 11. The sequence is much longer, and I guess that corresponds to H_w^w(3) (w is shorthand for omega) in the Hardy hierarchy, since 2 mapped on the ordinals (using your “g”) function is w^w, and H_w^w(3) is a number with 121210695 digits!
The first time, you replace R with 2 copies of R-1 (so 2 goes to 11). The second time, you replace it with 3 copies (so 11 goes to 101010). The third time, you replace it with 4 copies (so 1010 1 goes to 1010 0000), and so on. If c remained constant instead of increasing like that, then you’re stuck at f_4 instead of f_(epsilon_0).
Using Hardy hierarchy and comparisons with Jonathan Bowers’ array notation, I can state that T(3) is larger than {3,3,3,3,3}, which is known as pentatri in Bowers’ system.
Also, first strings of T(3) sequence is incorrect from 212121 → 212120212120212120212120 (it must be replaced to 212120212120212120, if we have 3 copies of R-1). If, however, we will write 4 copies of R-1, the number of steps exceeds {4,4,4,4,4,4} in array notation.
As I explained, the number of repeats ‘c’ increments every time you apply that operation. The current state of the process is thus represented by an ordered pair {c, S} of a positive integer c and a string S of positive integers.
Pingback: Busy beavers | Complex Projective 4-Space
Peter Hurford has written a similar post here: http://www.greatplay.net/essays/large-numbers-part-i-magnitude-and-simple-functions
It’s a good read, IMO.
About original C8: let f(n) is the number of steps which needed to reduce digit n into 1.
f(1) = 0, since 1 is already 1.
f(2) = 7, using sequence 2 => 11 => 1010 => 101 => 1000 => 100 => 10 => 1
f(3) = 206, using recursive considerations and verifying by brute-force search.
f(4) = 261822386976419231120746565236116726083, using only recursive considerations, of course.
Is it turn out that f(n) > 2^^n for all n>=2?
Corrected:
f(4) = 261822386976419231120746565236116726084 (to be exact)
C8′ appears to be a version of the so-called “worm game”, differing from it mainly by having a slightly more complicated rewrite rule. A few web-available references:
“The Worm Principle” (Beklemishev, 2003)
“Worms, Gaps and Hydras” (Carlucci, 2003)
“Die Another Day” (Fleischer, 2007)
A worm battle, starting with some initial worm w and counter value n, goes in steps like
(w,n) -> (w,n+1) -> … -> (e,n+k)
iterating a fixed rewrite rule until the worm is eventually reduced to the empty string e in k steps. This number of steps, written h_w(n), is a function of the initial (w,n). For comparison, here are the rewite rules for worms and for C8′, using the LR notation defined in the above article …
Worm game (involves one counter, n):
(L0,n) -> (L,n+1)
(LR,n) -> (L[R-1]^(n+1),n+1)
C8′ (involves two counters, n and m):
(L0,n,m) -> (L,n+1,m)
(LR,n,m) -> (L[R-1]^(m+1),n+1,m+1)
Note that in C8′ the counter m, which controls the number of copies in an expansion step, is incremented only on expansion steps, not on steps that delete a 0. Other differences are that C8′ always starts with n = m = 1 and stops when the worm is reduced to 1 (instead of when it’s empty).
Beklemeshev proves that every worm battle eventually terminates, and that this fact cannot be proved in Peano Arithmetic. Furthermore, he shows that the growth rate of h_n(n) is the same as that for corresponding Hydra games, which is f_eps0 in the fast growing hierarchy. From this, using h_n(1) > h_(n-c)(n-c) for some c, it follows that h_n(1) likewise has this same growth rate. Consequently, if C8′ were simplified to use n everywhere in place of m (so it becomes a worm game), then these same results would apply to the modified T() function — call it T'() — e.g., T'(2) = 25 instead of T(2) = 16.
Sorry, that should be
(w,n) -> (w_1,n+1) -> (w_2,n+2) -> … -> (e,n+k)
where, on the kth step, w_k = e (empty)
… and the name is spelled Beklemishev.
Sorry, that should be
(w,n) -> (w_1,n+1) -> (w_2,n+2) -> … -> (e,n+k)
where, on the kth step, w_k = e (empty)
… and the name is spelled Beklemishev.
Pingback: Variants on a problem – Moooosey's math blog