
2017 has been an unfortunate year for Fields medallists. Maryam Mirzakhani, who won the Fields medal in 2014, passed away at the untimely age of 40. Two days ago, she was joined by Vladimir Voevodsky, 2002 Fields medallist, who was awarded the prize for introducing a homotopy theory on schemes, uniting algebraic topology and algebraic geometry.
He also defined the ‘univalence axiom’ which underpins the recent area of homotopy type theory. This is an especially elegant approach to the foundations of mathematics, with several particularly desirable properties.
Problems with set theory
The most common foundation of mathematics is first-order ZFC set theory, where the objects are sets in the von Neumann universe. It is extremely powerful and expressive: all naturally-occurring mathematics seems to be readily formalised in ZFC. It does, however, involve somewhat arbitrary and convoluted definitions of relatively simple concepts such as the reals. Let us, for instance, consider how the real numbers are encoded in set theory:
A real is encoded as a Dedekind cut (down-set) of rationals, which are themselves encoded as equivalence classes (under scalar multiplication) of ordered pairs of an integer and a non-zero natural number, where an integer is encoded as an equivalence class (under scalar addition) of ordered pairs of natural numbers, where a natural number is a hereditarily finite transitive well-ordered set, and an ordered pair (a, b) is encoded as the pair {{a, b}, {a}}.
Whilst this can be abstracted away, it does expose some awkward concepts: there is nothing to stop you from asking whether a particular real contains some other set, even though we like to be able to think of reals as atomic objects with no substructure.
Another issue is that when we use ZFC in practice, we also have to operate within first-order predicate logic. So, whilst ZFC is considered a one-sorted theory (by contrast with NBG set theory which is two-sorted, having both sets and classes), our language is two-sorted: we have both Booleans and sets, which is why we need both predicate-symbols and function-symbols.
Type theory
In type theory, we have a many-sorted world where every object must have a type. When we informally write 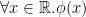

This idea of types should be familiar from most programming languages. In C, for instance, ‘double’ and ‘unsigned int’ are types. It is syntactically impossible to declare a variable such as x without stating its type; the same applies in type theory. Functional programming languages such as Haskell have more sophisticated type-theoretic concepts, such as allowing functions to be ‘first-class citizens’ of the theory: given types A and B, there is a type (A → B) of functions mapping objects of type A to objects of type B.
These parallels between type theory and computation are not superficial; they are part of a profound equivalence called the Curry-Howard isomorphism.
Types can themselves be objects of other types (in Python, this is familiar from the idea of a metaclass), and indeed every type belongs to some other type. Similar to the construction of the von Neumann hierarchy of sets, we have a sequence of nested universes, such that every type belongs to some universe. This principle, together with a handful of rules for building new types from old (dependent product types, dependent sum types, equality types, inductive types, etc.), is the basis for intuitionistic type theory. Voevodsky extended this with a further axiom, the univalence axiom, to obtain the richer homotopy type theory, which is sufficiently expressive to be used as a foundation for all mathematics.
Homotopy type theory
In type theory, it is convenient to think of types as sets and objects as elements. Homotopy type theory endows this with more structure, viewing types as spaces and objects as points within the space. Type equivalence is exactly the same notion as homotopy equivalence. More interestingly, given two terms a and b belonging to some type T, the equality type (a = b) is defined as the space of paths between a and b. From this, there is an inductive hierarchy of homotopy levels:
- A type is homotopy level 0 if it is contractible.
- A type is homotopy level n+1 if, for every pair of points a and b, the type (a = b) is homotopy level n.
They are nested, so anything belonging to one homotopy level automatically belongs to all greater homotopy levels (proof: the path spaces between two points in a contractible space are contractible, so level 1 contains level 0; the rest follows inductively). The first few homotopy levels have intuitive descriptions:
- Homotopy level 0 consists of contractible spaces, which are all equivalent types;
- Homotopy level 1 consists of empty and contractible spaces, called mere propositions, which can be thought of as ‘false’ and ‘true’ respectively;
- Homotopy level 2 consists of disjoint unions of contractible spaces, which can be viewed as sets (the elements of which are identified with the connected components);
- Homotopy level 3 consists of types with trivial homotopy in dimensions 2 and higher, which are groupoids;
- Homotopy level 4 consists of types with trivial homotopy in dimensions 3 and higher, which are 2-groupoids, and so on.
More generally, n-groupoids correspond to types of homotopy level n+2. The ‘sets’ (types in homotopy level 2) are more akin to category-theoretic sets than set-theoretic sets; there is no notion of sets containing other sets. I find it particularly beautiful how the familiar concepts of Booleans, sets and groupoids just ‘fall out’ in the form of strata in this inductive definition.
Voevodsky’s univalence property states that for two types A and B, the type of equivalences between them is equivalent to their equality type: (A ≈ B) ≈ (A = B). Note that the equality type (A = B) is the space of paths between A and B in the ambient universe U, so this is actually a statement about the universe U. A universe with this property is described as univalent, and the univalence axiom states that all universes are univalent.
Further reading
I definitely recommend reading the HoTT book — it is a well-written exposition of a beautiful theory.
[P. S. My partner and I are attending a debate this evening with Randall Munroe of xkcd fame. Watch this (cp4)space…]

 . Specifically, there is a preprocessing stage where extra bits are appended to the end of the input as follows:
. Specifically, there is a preprocessing stage where extra bits are appended to the end of the input as follows: . The use of a factorial to count the number of binary strings should immediately trigger alarm bells in anyone with a rudimentary undergraduate-level understanding of discrete mathematics.
. The use of a factorial to count the number of binary strings should immediately trigger alarm bells in anyone with a rudimentary undergraduate-level understanding of discrete mathematics.

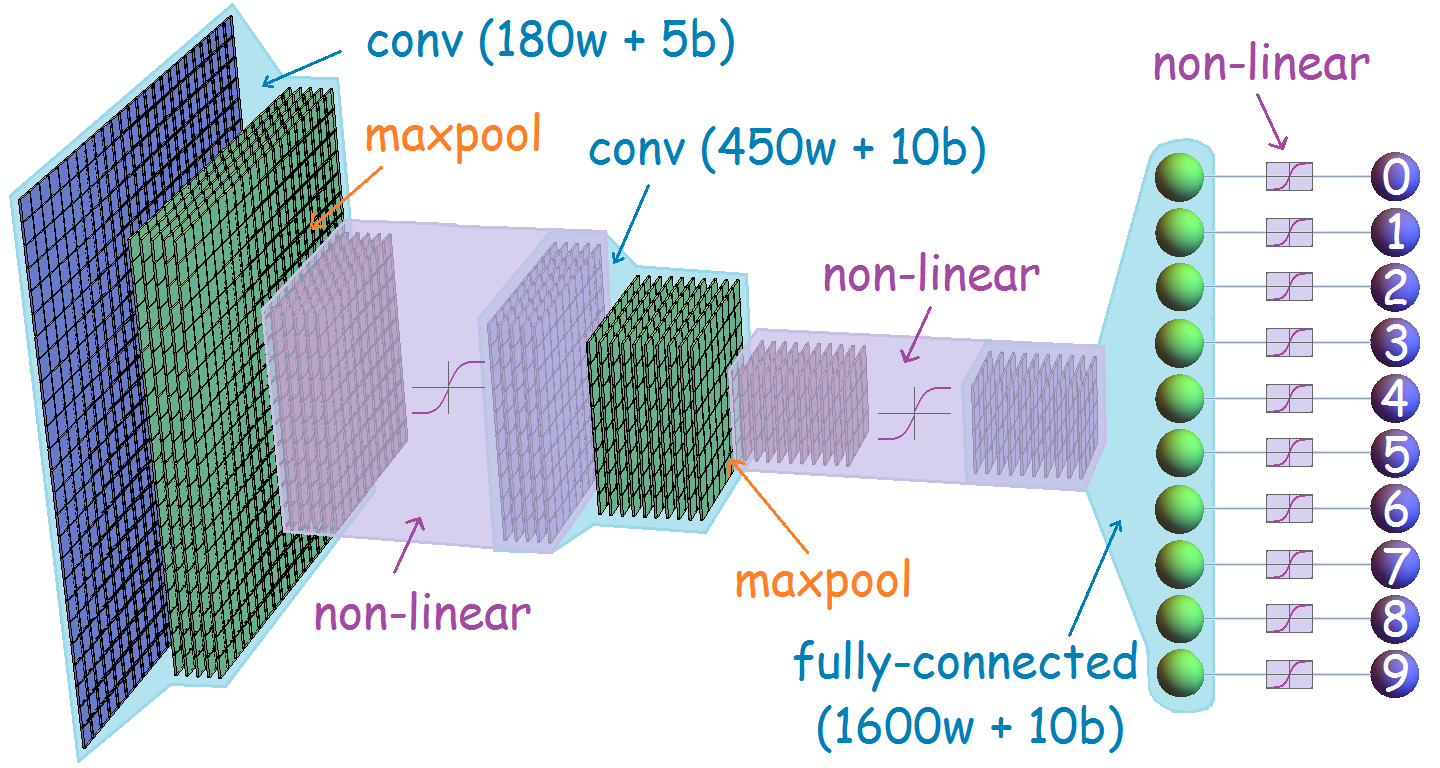
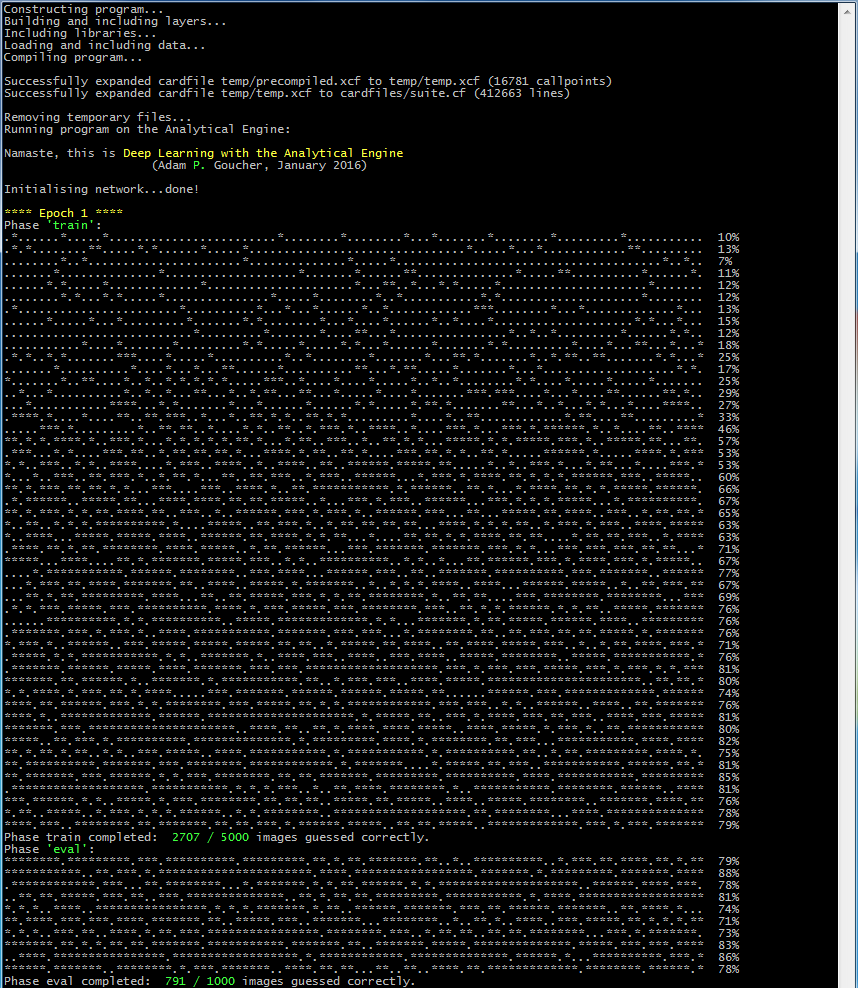





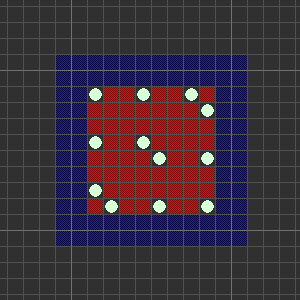

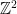 by means of a convolution. Specifically, each mine contributes a score to its own square and those surrounding it as follows:
by means of a convolution. Specifically, each mine contributes a score to its own square and those surrounding it as follows:

 or the torus obtained by quotienting by a lattice. Gaussian kernels are often used.
or the torus obtained by quotienting by a lattice. Gaussian kernels are often used.