A new form of artificial life has been born — and there are no doubts that it directs its own self-replication:
So, what exactly is happening?
- At 0:06, the organism begins to sequentially construct four identical copies of itself.
- At 0:14, the original organism self-destructs to leave room for its offspring.
- At 0:16, each of the four children begin to sequentially construct copies of themselves. By 0:18, there are eight organisms.
- By 0:24, there are a total of thirteen organisms.
- At 0:27, the four from the previous generation self-destruct, followed shortly by the eight outermost organisms.
- By 0:34, the apoptosis of the outermost organisms finishes, leaving behind a clean isolated copy indistinguishable from the original cell.
How does it work? Why did the cells suddenly choose to die, and how did the middle cell know that it was due to survive? And how does this relate to multicellular life?
Update, 2019-05-12: Here’s a high-definition video of the construction of the south-east daughter machine:
History
The field of artificial life is often ascribed to Christopher Langton’s self-replicating loops. We have discussed these previously. A sequence of simple LOGO-like instructions circulate in an ensheathed loop. This information is executed 4 times to construct another copy of the loop (taking advantage of the symmetry of the daughter loop), and then the same tape is copied into the daughter loop:

Langton’s loop
If we quantify the number of times the loop’s instruction tape is utilised, we can represent it as the formal sum 4E + 1C (where ‘E’ represents one tape execution and ‘C’ represents tape copying).
However, there’s more. If the loop were only able to produce one child, the number of fertile loops would remain bounded (at 1), and it is disputed whether such bounded-fecundity ‘linear propagators‘ are actually true self-replicators. Note that at the end of the animation above, the loop has extended a new pseudopodium upwards, and will begin constructing a second offspring.
This continues for each of the sides of the parent loop, thereby giving an overall tape utility of 4(4E + 1C) = 16E + 4C. Note that the inner ‘4E’ comes from the fourfold symmetry of the daughter loop, whereas the outer ‘4E’ comes from the fourfold symmetry of the parent loop.
Anyway, after a while, the colony of self-replicating loops resemble this:

Colony of Langton’s self-replicating loops. The number of fertile loops grows linearly without bound, and the total number of loops (including the necrotic core at the centre) grows quadratically as a function of time.
Race to the bottom
Five years after Langton’s loops were invented, John Byl removed the inner sheath of the loop to result in a more minimalistic self-replicator, with only 4 tape cells surrounded by 8 sheath cells:

Byl’s simpler self-replicating loop. Image courtesy of Claudio Rocchini
Moreover, the underlying rule is simpler: only 6 states instead of 8. This comes at the expense of reduced flexibility; whereas one could build a larger Langton’s loop by increasing each side-length by n and inserting n ‘move forward’ instructions into the loop, there is no way to construct a Byl loop with any other genome.
Nor does it stop with Byl. In 1993, Chou and Reggia removed the outer sheath from the loop by adding two more states (returning to 8, same as Langton). The loops, which are barely recognisable as such, are only 6 cells in size: half of Byl’s loop and an order of magnitude smaller than Langton’s.
If minimality were the only concern, all of these examples would be blown out of the water by Edward Fredkin’s single-cell replicator in the 2-state XOR rule. However, every configuration in that rule replicates, including a photograph of Fredkin, so it is hard to claim that this is self-directed.
Ancestors of Langton’s Loops
The inspiration for Langton’s loop was an earlier (1968) 8-state cellular automaton by E. F. Codd (the inventor of the relational database). Codd’s cellular automaton was designed to support universal computers augmented with universal construction capabilities: unlike Langton’s loops, the instruction tape can program the machine to build any configuration of quiescent cells, not just a simple copy of itself.
It took until 2010 before Codd’s machine was actually built, with some slight corrections, by Tim Hutton. It is massive:

Tim Hutton’s implementation of Codd’s self-replicating computer
Codd’s cellular automaton itself was borne out of a bet in a pub, where Codd challenged a friend that he could create a self-replicating computer in a cellular automaton with fewer states than von Neumann’s original 29-state cellular automaton.
Comparison of replicators
For an n-state k-neighbour cellular automaton, there are 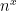 different rules, where
different rules, where 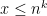 is the number of distinct neighbourhoods that can occur. (We get equality
is the number of distinct neighbourhoods that can occur. (We get equality  in the case of asymmetric rules, but for rules with symmetries the count is more complex and depends on the Polya Enumeration Theorem.) Consequently, we can concretely define the ‘complexity’ of the rule (in bits) to be
in the case of asymmetric rules, but for rules with symmetries the count is more complex and depends on the Polya Enumeration Theorem.) Consequently, we can concretely define the ‘complexity’ of the rule (in bits) to be 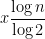 .
.
For instance, Langton’s, Codd’s and Chou-Reggia’s cellular automata all have a complexity of 25056 bits, whereas Nobili’s 32-state adaptation of von Neumann’s original 29-state rule has a complexity of 167772160 bits. Conway’s two-state rule, by comparison, has only 18 bits of complexity.
We can plot the population count (including the tape) of different self-replicating machines on one axis, and the complexity of the rule on the other axis. Interestingly, qualitative categories of replicator such as ‘universal constructor’, ‘loop’, and ‘parity-rule replicator’ form visually distinct clusters in the space:
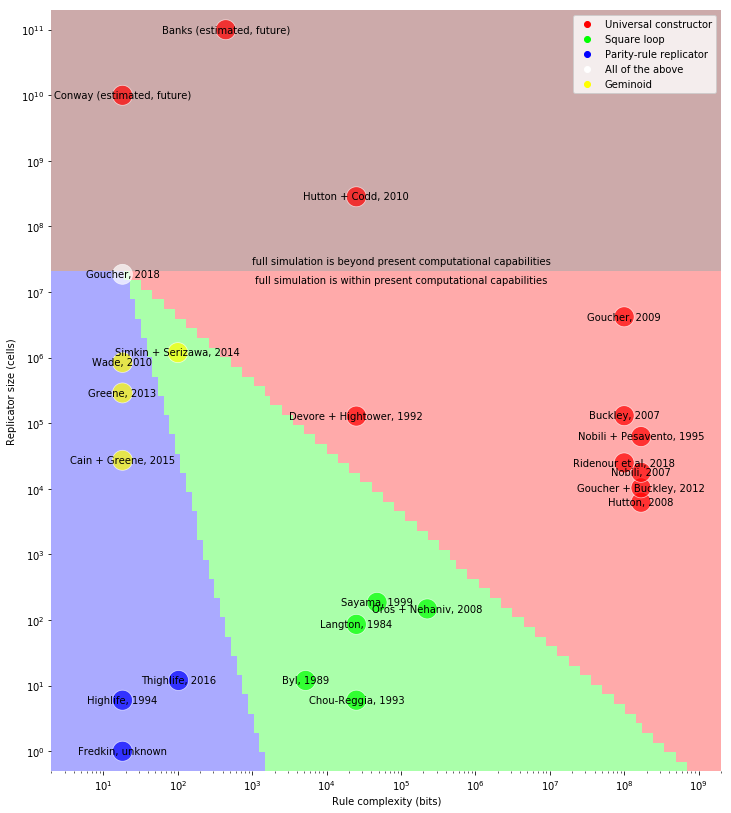
Near the top of the plot are two rough hypothetical designs of replicators which have never been built:
- Conway’s original blueprint for a universal constructor in his 2-state 9-neighbour cellular automaton, as described in Winning Ways and The Recursive Universe;
- An estimate of how large a self-replicating machine would need to be in Edwin Roger Banks’ ‘Banks-IV‘ cellular automaton, described in his 1971 PhD thesis.
The third point from the top (Codd’s 1968 self-replicating computer) also fell into this category, until Tim Hutton actually constructed the behemoth. This has been estimated to take 1000 years to replicate, which is why it is firmly above the threshold of ‘full simulation is beyond present computational capabilities’.
Everything else in this plot has been explicitly built and simulated for at least one full cycle of replication. Immediately below Codd’s machine, for instance, is Devore’s machine (built by Hightower in 1992), which is much more efficient and can be simulated within a reasonable time. The other patterns form clusters in the plot:
- On the right-hand side of the plot is a cluster of self-replicating machines in von Neumann cellular automata, along with Renato Nobili’s and Tim Hutton’s modifications of the rule.
- The green points in this centre at the bottom are loop-like replicators. As well as Langton’s loops, this includes evolvable variants by Sayama and Oros + Nehaniv.
- The bottom-left cluster comprises trivial parity-rule replicators which have no tape and are passively copied by the underlying rule.
The yellow points on the left edge are self-propagating configurations which move by universal construction, but are not replicators in the strictest sense. They are all bounded-fecundity self-constructors, and with the exception of Greene 2013, they do not even copy their own tapes.
Why is the new organism interesting?
Finally, we have the new organism (shown in white on the left-hand side of the log-log plot, immediately below the threshold of practicality). Suitably programmed, this is a parity-rule replicator, and a loop-like replicator, and a universal constructor. It is also the first unbounded-fecundity replicator in Conway’s 2-state cellular automaton.
If we look again at the video:
we can see that, macroscopically, it copies itself in all four directions similar to Langton’s loops. The circuitry is designed such that each new child is placed in the same orientation and phase as the parent. Moreover, we see that the organism is programmed to self-destruct — either before or after constructing up to four children.
Whether or not it self-destructs prematurely depends on what signals it has received from its neighbours. Effectively, the machine receives a signal (a positive integer between 1 and 7, inclusive) from each of the (up to four) neighbours, and a 0 from any empty spaces if there are fewer than four neighbours. It then computes the quantity 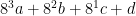 , where (a, b, c, d) are the four input signals, and indexes into a 4096-element lookup table to retrieve a value between 0 and 7 (the new ‘state’ of the machine). If 0, it immediately self-destructs without constructing any children; if nonzero, it constructs a daughter machine in each vacant space. Finally, it broadcasts the new state as a signal to all four neighbours, before self-destructing anyway.
, where (a, b, c, d) are the four input signals, and indexes into a 4096-element lookup table to retrieve a value between 0 and 7 (the new ‘state’ of the machine). If 0, it immediately self-destructs without constructing any children; if nonzero, it constructs a daughter machine in each vacant space. Finally, it broadcasts the new state as a signal to all four neighbours, before self-destructing anyway.
In doing so, this loop-like replicator behaves as a single cell in any 8-state 4-neighbour cellular automaton; the rule is specified by the lookup table inside the replicator. We call this construct a metacell because it emulates a single cell in a (8-state 4-neighbour) cellular automaton using a large collection of cells in the underlying (2-state 9-neighbour) cellular automaton.
This is not the first metacell (David Bell’s Unit Life Cell being the first example), but it is unique in having a 0-population ground state. As such, unlike the Unit Life Cell (which requires the entire plane to be tiled with infinitely many copies), any finite pattern in the emulated rule can be realised as a finite pattern in the underlying rule.
Interestingly, every 2-state 9-neighbour cellular automaton can be emulated at half the speed as an 8-state 4-neighbour cellular automaton. As such, we can ‘import’ any pattern from any such cellular automaton into Conway’s rule, thereby obtaining the first examples of:
- a parity-rule replicator (by emulating Fredkin, HighLife, or ThighLife);
- a reflectorless rotating oscillator;
- a spaceship made of perpetually colliding copies of smaller spaceships;
or even the metacell itself, recursively, obtaining an infinite sequence of exponentially larger and slower copies thereof (as if the existing metacell isn’t already too large and slow!).
To simplify the process of ‘metafying’ a pattern from an arbitrary isotropic 2-state 9-neighbour cellular automaton, I have included a Python script; this programs the metacell for the desired rule and assembles many copies (one for each cell in the original pattern) thereof into an equivalent pattern ‘writ large’.
Next time, we shall discuss in greater detail how the metacell itself was built. Until then, you may want to read Dave Greene’s recent article about some of the technology involved.







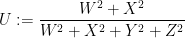



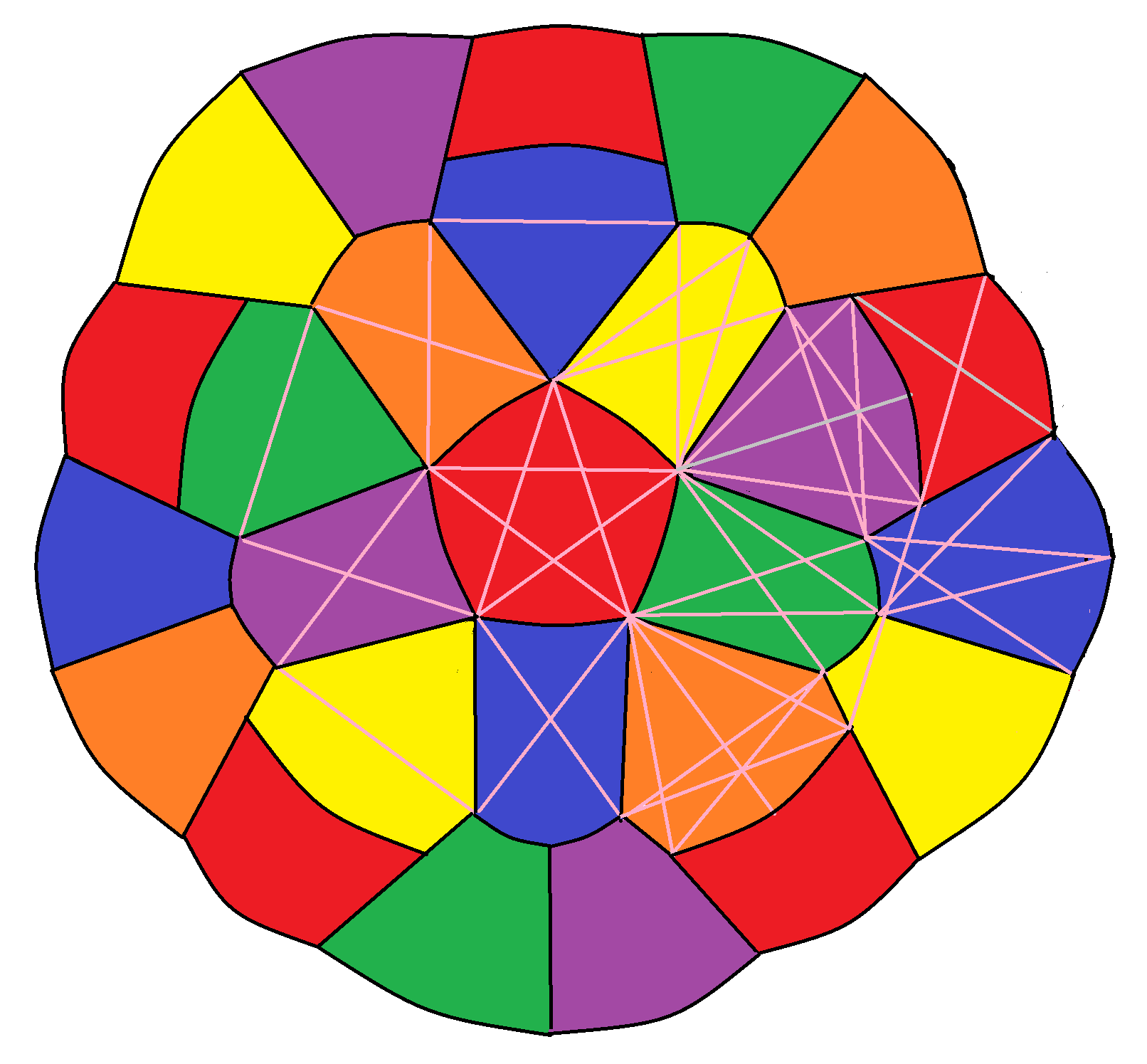
 can similarly be 6-coloured in a
can similarly be 6-coloured in a 



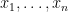 in the three-dimensional unit ball. Let the ray (half-line) from
in the three-dimensional unit ball. Let the ray (half-line) from  through
through 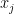 meet the boundary of the ball at
meet the boundary of the ball at  , viewed as a complex number on the Riemann sphere. We define the monic polynomials
, viewed as a complex number on the Riemann sphere. We define the monic polynomials  whose roots are given by the projections of the remaining points onto the sphere.
whose roots are given by the projections of the remaining points onto the sphere.
![f : Ireland \rightarrow [0, 1]](https://s0.wp.com/latex.php?latex=f+%3A+Ireland+%5Crightarrow+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) such that
such that  is identically 0 on Northern Ireland and identically 1 on the Republic of Ireland.
is identically 0 on Northern Ireland and identically 1 on the Republic of Ireland. :
:
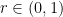 with denominator
with denominator  and odd numerator:
and odd numerator:
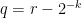 and
and  , so
, so 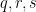 are adjacent;
are adjacent; (where the infimum of an empty set is taken to be 1).
(where the infimum of an empty set is taken to be 1).